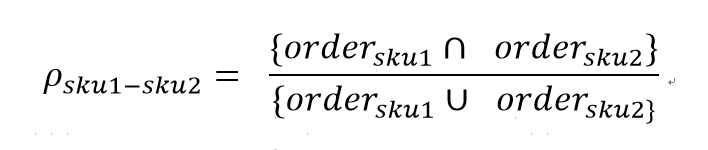同步于CSDN ;音尘杂记
在实际项目中,对超大矩阵进行计算或者对超大的DataFrame进行计算是一个经常会出现的场景。这里先不考虑开发机本身内存等客观硬件因素,仅从设计上讨论一下不同实现方式带来的性能差异,抛砖引玉。
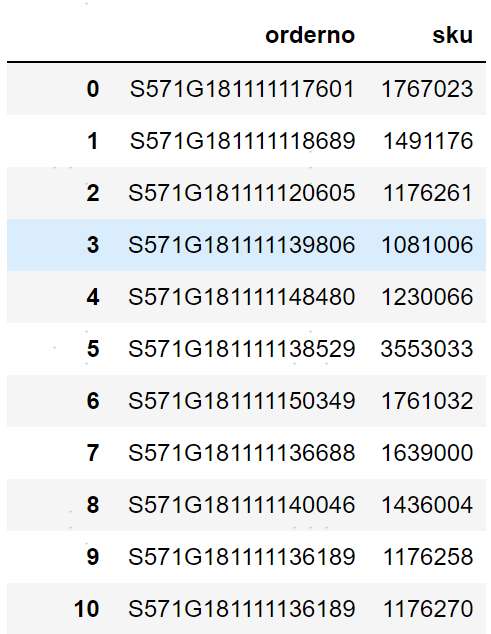
项目中有这样一个需求,需要根据历史销量数据计算SKU(Stock Keeping Unit)之间的相似度,或者更通俗一点说是根据历史销量数据求不同SKU之间出现的订单交集以及并集大小(注:SKU数量大概15k左右,订单数大概1000k左右)。
这里给几条示例数据,可以更直观形象地理解这个需求:
然后需要根据这些历史的orderno-sku(订单-商品)数据求解出sku的相似度矩阵。其中SKU1和SKU2之间的相似度定义为:
可以很快速地想到几种解决方案:
直接for loops;
for loops稍微改进采用列表生成器;
采用多进程并行计算;
采用numpy.vectorize
1.for loops计算相似度矩阵 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @timer def gen_corr_matrix_for_loops (order_df ): """ for loops计算相似度矩阵 """ df = order_df.groupby(['sku' ]).agg({'orderno' : lambda x: set (x)}).reset_index() del order_df gc.collect() l = len (df) sku_series = df.sku.astype(str ) corr_matrix_arr = np.ones((l, l)) tbar = trange(l) tbar.set_description("compute corr matrix" ) for i in tbar: for j in range (i + 1 , l): corr_matrix_arr[j, i] = corr_matrix_arr[i, j] = len (df.iloc[i, 1 ] & df.iloc[j, 1 ]) / len ( df.iloc[i, 1 ] | df.iloc[j, 1 ]) corr_matrix_df = pd.DataFrame(columns=sku_series, index=sku_series, data=corr_matrix_arr) return corr_matrix_df
计算耗时:2000s+
2.list generator计算相似度矩阵 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @timer def gen_corr_matrix_generator (order_df ): """ 列表生成器计算相似度矩阵 """ df = order_df.groupby(['sku' ]).agg({'orderno' : lambda x: set (x)}).reset_index() del order_df gc.collect() l= len (df) sku_series = df.sku.astype(str ) corr_matrix_arr = np.ones((l, l)) l1 = df.orderno l2 = np.array(df['orderno' ].apply(len ), dtype=np.int8) result_list = [[i, j, len (l1[i] & l1[j])] for i in range (l) for j in range (i+1 , l) if len (l1[i] & l1[j]) > 0 ] for i, j, k in result_list: corr_matrix_arr[j, i] = corr_matrix_arr[i, j] = k * 1.0 / (l2[i] + l2[j] - k) corr_matrix_df = pd.DataFrame(columns=sku_series, index=sku_series, data=corr_matrix_arr) return corr_matrix_df
计算耗时:1296s
3.多进程计算相似度矩阵 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 @timer def gen_corr_matrix_multiprocessing (order_df ): """ 多进程计算相似度矩阵 """ df = order_df.groupby(['sku' ]).agg({'orderno' : lambda x: set (x)}).reset_index() del order_df gc.collect() l = len (df) sku_series = df.sku.astype(str ) l1 = df.orderno l2 = np.array(df['orderno' ].apply(len ), dtype=np.int8) del df gc.collect() arr2 = np.zeros((l, l), dtype=np.float32) pairs = [[i, j] for i in range (l - 1 ) for j in range (i + 1 , l)] loops = int (math.ceil((l ** 2 - l) / 10 ** 6 / 2 )) tbar = trange(loops) tbar.set_description("compute corr matrix" ) pool = Pool(4 ) for loop in tbar: temp_lists = [[i, j, l1[i], l1[j]] for i, j in pairs[(10 ** 6 * loop): (10 ** 6 * (loop + 1 ))]] temp_results = pool.map (cal, temp_lists) for i, j, k in temp_results: arr2[i, j] = k pool.close() pool.join() arr1 = l2 + l2.reshape((l, 1 )) arr2 = arr2 + arr2.T arr3 = arr2 / (arr1 - arr2) + np.eye(l) del arr1 del arr2 gc.collect() corr_matrix_df = pd.DataFrame(columns=sku_series, index=sku_series, data=arr3) return corr_matrix_df
计算耗时:1563s
4.numpy.vectorize计算相似度矩阵 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @timer def gen_corr_matrix_vectorize (order_df ): """ numpy.vectorice计算相似度矩阵 """ df = order_df.groupby(['sku' ]).agg({'orderno' : lambda x: set (x)}).reset_index() l = len (df) sku_series = df.sku.astype(str ) arr = df.orderno.values corr_matrix_arr = np.zeros((l, l)) f_vec = np.vectorize(len ) arr1 = f_vec(arr) tbar = trange(l - 1 ) tbar.set_description("compute corr matrix" ) for i in tbar(l - 1 ): corr_matrix_arr[i, (i + 1 ): l] = f_vec(arr[(i + 1 ): l] & arr[i]) corr_matrix_arr1 = np.add.outer(arr1, arr1) temp = corr_matrix_arr / (corr_matrix_arr1 - corr_matrix_arr) temp = temp + temp.T + np.eye(l) return pd.DataFrame(columns=sku_series, index=sku_series, data=temp)
计算耗时:72s
可以看到,使用numpy.vectorize提升了20倍左右!
思考: