【Spark】Pipelines
在本节中,我们将介绍ML Pipelines的概念。 ML Pipelines提供了一组基于DataFrame构建的统一的高级API,可帮助用户创建和调整实用的机器学习流程。
1. 管道中的主要概念
MLlib标准化用于机器学习算法的API,以便更轻松地将多个算法组合到单个管道或工作流程中。本节介绍Pipelines API引入的关键概念,其中管道概念主要受到scikit-learn项目的启发。
DataFrame:此ML API使用Spark SQL中的DataFrame作为ML数据集,它可以包含各种数据类型。例如,DataFrame可以具有存储文本,特征向量,标签(true labels)和预测的不同列。
Transformer:Transformer是一种可以将一个DataFrame转换为另一个DataFrame的算法。例如,ML模型是变换器,其将具有特征的DataFrame转换为具有预测的DataFrame。
Estimator:Estimator是一种算法,可以适应DataFrame以生成Transformer。例如,学习算法是Estimator,其在DataFrame上训练并产生模型。
Pipeline:管道将多个Transformers和Estimators链接在一起以指定ML工作流程。
参数:所有Transformers和Estimators现在共享一个用于指定参数的通用API。
1.1 DataFrame
机器学习可以应用于各种数据类型,例如矢量,文本,图像和结构化数据。 此API采用Spark SQL的DataFrame以支持各种数据类型。
DataFrame支持许多基本和结构化类型; 有关支持的类型列表,请参阅Spark SQL数据类型参考。 除了Spark SQL指南中列出的类型之外,DataFrame还可以使用ML Vector类型。
可以从常规RDD隐式或显式创建DataFrame。 有关示例,请参阅下面的代码示例和Spark SQL编程指南。
DataFrame中的列已命名。 下面的代码示例使用诸如“text”,“features”和“label”之类的名称。
1.2 Pipeline 组件
1.2.1 Transformers
Transformer是一种抽象,包括特征变换器和学习模型。 从技术上讲,Transformer实现了一个方法transform(),它通常通过附加一个或多个列将一个DataFrame转换为另一个DataFrame。 例如:
- 特征变换器可以采用DataFrame,读取列(例如,文本),将其映射到新列(例如,特征向量),并输出附加了映射列的新DataFrame。
- 学习模型可以采用DataFrame,读取包含特征向量的列,预测每个要素向量的标签,并输出新的DataFrame,其中预测标签作为列附加。
1.2.2 Estimators
估计器抽象学习算法或适合或训练数据的任何算法的概念。 从技术上讲,Estimator实现了一个方法fit(),它接受一个DataFrame并生成一个Model,它是一个Transformer。 例如,诸如LogisticRegression之类的学习算法是Estimator,并且调用fit()训练LogisticRegressionModel,LogisticRegressionModel是Model并因此是Transformer。
1.2.3 Pipeline组件的属性
Transformer.transform()和Estimator.fit()都是无状态的。 将来,可以通过替代概念支持有状态算法。
Transformer或Estimator的每个实例都有一个唯一的ID,可用于指定参数(如下所述)。
1.3 Pipeline
在机器学习中,通常运行一系列算法来处理和学习数据。 例如,简单的文本文档处理工作流程可能包括几个阶段:
- 将每个文档的文本拆分为单词。
- 将每个文档的单词转换为数字特征向量。
- 使用特征向量和标签学习预测模型。
MLlib将此类工作流表示为管道,其由一系列以特定顺序运行的PipelineStages(变换器和估算器)组成。我们将在本节中将此简单工作流用作运行示例。
1.3.1 运行原理
管道被指定为不同阶段的序列,并且每个阶段是变换器或估计器。 这些阶段按顺序运行,输入DataFrame在通过每个阶段时进行转换。 对于Transformer阶段,在DataFrame上调用transform()方法。 对于Estimator阶段,调用fit()方法以生成Transformer(它成为PipelineModel或拟合管道的一部分),并在DataFrame上调用Transformer的transform()方法。
我们为简单的文本文档工作流说明了这一点。 下图是管道的训练时间使用情况。
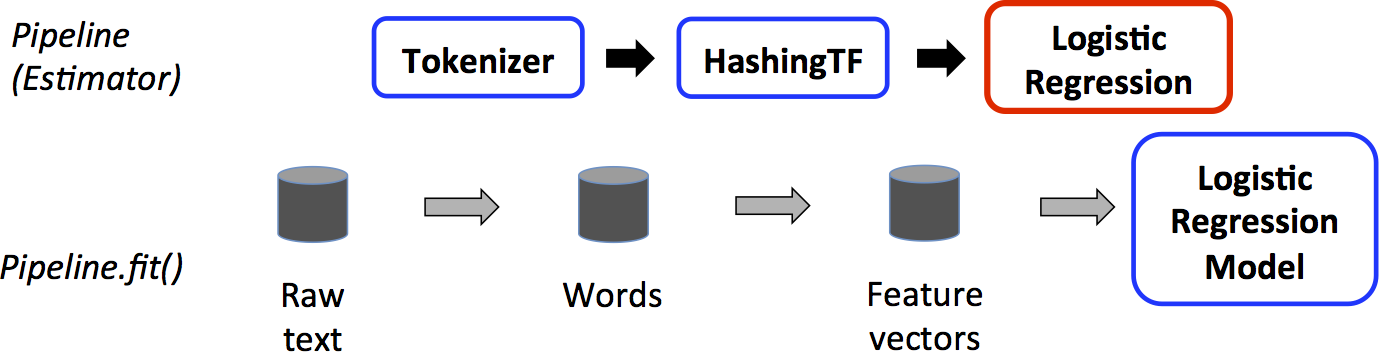
上图中,顶行表示具有三个阶段的管道。前两个(Tokenizer和HashingTF)是TransformerS(蓝色),第三个(LogisticRegression)是Estimator(红色)。底行表示流经管道的数据,其中柱面表示DataFrame。在原始DataFrame上调用Pipeline.fit()方法,该原始DataFrame具有原始文本文档和标签。 Tokenizer.transform()方法将原始文本文档拆分为单词,向DataFrame添加一个带有单词的新列。 HashingTF.transform()方法将单词列转换为要素向量,将包含这些向量的新列添加到DataFrame。现在,由于LogisticRegression是一个Estimator,因此Pipeline首先调用LogisticRegression.fit()来生成LogisticRegressionModel。如果Pipeline有更多的Estimators,它会在将DataFrame传递给下一个阶段之前在DataFrame上调用LogisticRegressionModel的transform()方法。
一个Pipeline是Estimator。因此,在Pipeline的fit()方法运行之后,它会生成一个PipelineModel,它是一个Transformer。这个PipelineModel在测试时使用;下图说明了这种用法。
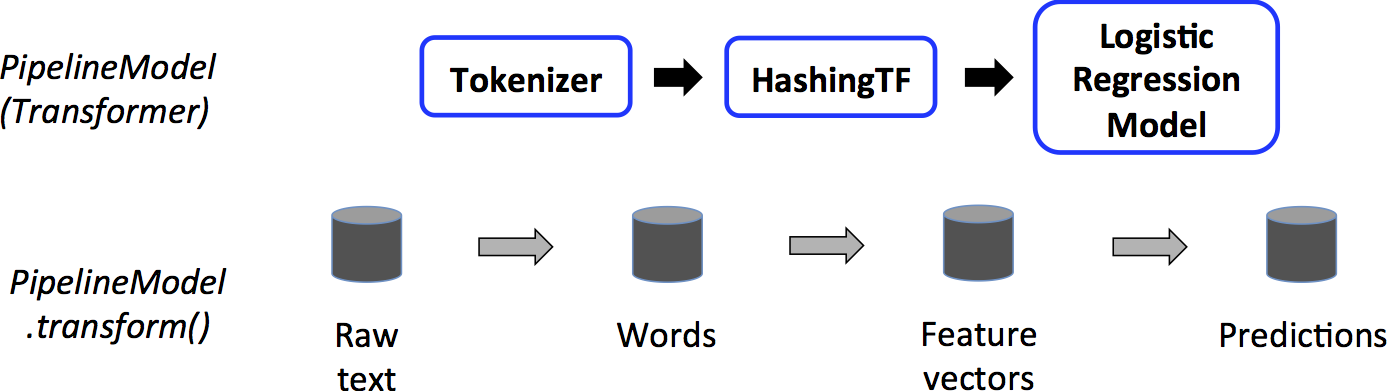
在上图中,PipelineModel具有与原始Pipeline相同的阶段数,但原始Pipeline中的所有Estimators都变为Transformers。 当在测试数据集上调用PipelineModel的transform()方法时,数据将按顺序通过拟合的管道传递。 每个阶段的transform()方法都会更新数据集并将其传递给下一个阶段。
Pipelines和PipelineModel有助于确保训练和测试数据经过相同的功能处理步骤。
1.3.2 详细过程
DAG PipelineS:管道的阶段被指定为有序数组。这里给出的例子都是线性管道(linear PipelineS),即其中每个阶段的管道使用前一阶段产生的数据。只要数据流图形成有向无环图(DAG),就可以创建非线性管道。目前,此图基于每个阶段的输入和输出列名称(通常指定为参数)隐式指定。如果管道形成DAG,则必须按拓扑顺序指定阶段。
运行时检查:由于Pipelines可以在具有不同类型的DataFrame上运行,因此它们不能使用编译时类型检查。 Pipelines和PipelineModels代替在实际运行Pipeline之前进行运行时检查。此类型检查是使用DataFrame模式完成的,DataFrame模式是DataFrame中列的数据类型的描述。
独特的管道阶段:管道的阶段应该是唯一的实例。例如,由于Pipeline阶段必须具有唯一ID,因此不应将相同的实例myHashingTF插入到Pipeline中两次。但是,不同的实例myHashingTF1和myHashingTF2(都是HashingTF类型)可以放在同一个管道中,因为将使用不同的ID创建不同的实例。
1.4 参数
MLlib Estimators和Transformers使用统一的API来指定参数。
Param是一个带有自包含文档的命名参数。 ParamMap是一组(参数,值)对。
将参数传递给算法有两种主要方法:
- 设置实例的参数。 例如,如果lr是LogisticRegression的实例,则可以调用lr.setMaxIter(10)以使lr.fit()最多使用10次迭代。 此API类似于spark.mllib包中使用的API。
- 将ParamMap传递给fit()或transform()。 ParamMap中的任何参数都将覆盖先前通过setter方法指定的参数。
参数属于Estimators和Transformers的特定实例。 例如,如果我们有两个LogisticRegression实例lr1和lr2,那么我们可以构建一个指定了两个maxIter参数的ParamMap:ParamMap(lr1.maxIter - > 10,lr2.maxIter - > 20)。 如果管道中有两个带有maxIter参数的算法,这将非常有用。
1.5 ML持久性:保存和加载管道
通常,将模型或管道保存到磁盘以供以后使用是值得的。 在Spark 1.6中,模型导入/导出功能已添加到Pipeline API中。 从Spark 2.3开始,spark.ml和pyspark.ml中基于DataFrame的API具有完整的覆盖范围。
ML持久性适用于Scala,Java和Python。 但是,R当前使用的是修改后的格式,因此保存在R中的模型只能加载回R; 这应该在将来修复,并在SPARK-15572中进行跟踪。
1.5.1 ML持久性的向后兼容性
通常,MLlib保持ML持久性的向后兼容性。即,如果您在一个版本的Spark中保存ML模型或Pipeline,那么您应该能够将其加载回来并在将来的Spark版本中使用它。但是,极少数例外情况如下所述。
模型持久性:Spark版本Y可以加载Spark版本X中使用Apache Spark ML持久性保存模型或管道吗?
- 主要版本:没有保证,但是尽力而为。
- 次要和补丁版本:是的;这些是向后兼容的。
- 关于格式的注意事项:不保证稳定的持久性格式,但模型加载本身设计为向后兼容。
模型行为:Spark版本X中的模型或管道在Spark版本Y中的行为是否相同?
- 主要版本:没有保证,但是尽力而为。
- 次要和补丁版本:相同的行为,除了错误修复。
对于模型持久性和模型行为,在Spark版本发行说明中报告了次要版本或修补程序版本的任何重大更改。如果发行说明中未报告破损,则应将其视为要修复的错误。
2. 代码示例
本节给出了说明上述功能的代码示例(仅仅附上基于Python的示例代码)。 有关详细信息,请参阅这里。
2.1 示例:Estimator,Transformer和Param
此示例涵盖Estimator,Transformer和Param的概念。
1 | # -*- coding: utf-8 -*- |
如上代码在windows 10 | Pycharm | Spark 2.3.2中测试通过。中间日志很多,只附上最后的预测结果:
1 | features=[-1.0,1.5,1.3], label=1.0 -> prob=[0.057073041710340174,0.9429269582896599], prediction=1.0 |
2.2 示例: Pipeline
此示例遵循上图中所示的简单文本文档Pipeline。
1 | # -*- coding: utf-8 -*- |
测试结果如下:
1 | (4, spark i j k) --> prob=[0.1596407738787475,0.8403592261212525], prediction=1.000000 |
2.3 模型选择(超参数调整)
使用ML Pipelines的一大好处是超参数优化。 有关自动模型选择的更多信息,请参阅这里。
【Spark】Pipelines