【Graph Embedding】struc2vec
关于Graph Embedding系列的论文翻译解读文章:
参考资料
paper: https://arxiv.org/pdf/1704.03165.pdf
code: https://github.com/leoribeiro/struc2vec
摘要
结构一致性是一个对称的概念,其中网络节点是根据网络结构及其与其他节点的关系来识别的。结构一致性在过去的几十年里已经在理论和实践中得到了研究,但直到最近才被表征性学习技术解决。这项工作提出了struc2vec,这是一种新颖且灵活的框架,用于学习节点结构身份的潜在表示。使用层次结构来测量不同尺度下的节点相似性,并构建多层图来编码结构相似性并生成节点的结构上下文。数值实验表明,最先进的节点表示学习技术未能捕获更强的结构身份概念,而struc2vec在这一任务中表现出更优越的性能,因为它克服了之前方法的限制。因此,数值实验表明,struc2vec提高了更多依赖于结构特性的分类任务的性能。
1. 介绍
在几乎所有的网络中,节点往往具有一个或多个功能,这些功能在很大程度上决定了它们在系统中的角色。例如,社交网络中的社会角色和社会地位[11、19],而蛋白质-蛋白质交互(PPI)网络施加specific函数[1,22]。直观地说,这些网络中的不同节点可能执行类似的功能,例如企业社交网络中的实习生,或者细胞PPI网络中的催化剂。根据节点在网络中的作用,可以将节点划分为等价的类。虽然当节点功能完全由网络结构决定时,就出现了利用节点的功能描述。在这种情况下,甚至连节点的标签也不是,而是它们与其他节点(边)的关系。事实上,自20世纪70年代以来,数学社会学家一直在研究这个问题,他们设计并计算社会网络中个体的结构身份[11,17,19]。除了社会学,webgraph中网页的角色是从网络结构中出现另一个身份(在这里是中心和权威)的例子,正如Kleinberg[8]的著名著作所描述的那样。
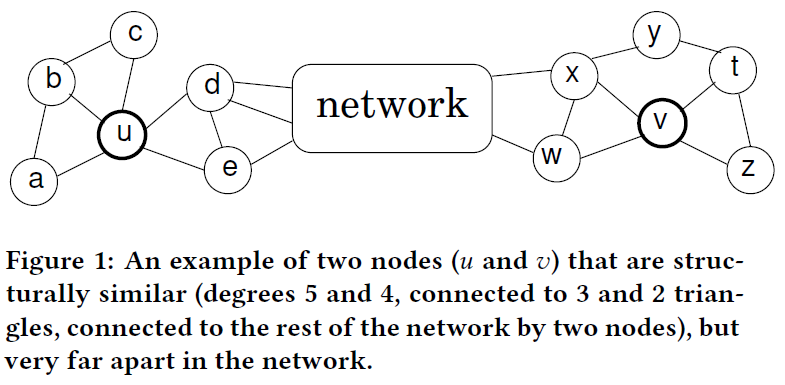
最常见的确定节点结构身份的实用方法是基于距离或递归。在前者中,利用节点的邻域的距离函数来测量所有节点对之间的距离,然后进行聚类或匹配,将节点放入等价的类中[5,9]。在后一种方法中,构造一个关于邻近节点的递归,然后迭代展开,直到收敛,使用最终值确定等价类[3,8,26]。虽然这种方法有优点和缺点,我们提供了一种替代方法,一种基于无监督学习的表示节点的结构身份。最近在学习网络中节点的潜在表示方面的研究在分类和预测任务方面取得了很大的成功[6,14,16,23]。特别是,这些工作将节点作为上下文编码,使用它们的邻居的一个通用概念(例如,随机游走的第w步,或具有共同邻居的节点)。简而言之,具有相似节点集的邻域的节点应该具有相似的潜在表示。但是邻域是由网络中的邻近性概念所决定的局部概念。因此,如果两个节点的邻居在结构上相似,但相距很远,则不会有相似的潜在表示。图1说明了这个问题,其中节点$u$和$v$扮演类似的角色(即但是在网络中它们之间的距离非常远。由于它们的邻居没有公共节点,所以最近的方法无法捕捉它们的结构相似性。
值得注意的是,最近用于学习节点表示的方法(如DeepWalk[16]和node2vec[6])在分类任务中成功,但在结构等价任务中往往失败。关键在于,在大多数真实网络中,许多节点特征表现出很强的同质性(例如,具有相同政治倾向的两个博客比随机连接的可能性要大得多)。具有给定特性的节点的邻居更有可能具有相同的特性。在我们看来,网络中距离较近的节点和潜在表示的节点往往具有相同的特征。同样地,网络中较远的两个节点也会倾向于在潜在表示中被分开,独立于它们的局部结构。因此,结构上的等价性将不能被适当地捕获在潜在的表示中。然而,如果对更多依赖于结构一致性而较少依赖于同质性的特征进行分类,那么这些最近的方法可能会被捕获结构等价的潜在表征所超越。
我们的主要贡献是一个可行的框架,用于学习节点结构身份的潜在表示,称为struc2vec。它是通过潜在表征研究结构一致性的一种替代和有力的工具。struc2vec的主要思想是:
- 评估独立于节点和边缘的节点之间的结构相似性,以及它们在网络中的位置。因此,两个具有相似的局部结构的节点将被认为是独立于其邻域内的网络位置和节点标签的。我们的方法也不需要连接网络,并且在不同的连接组件中定义了结构上类似的节点。
- 建立一个等级体系来衡量结构相似性,允许对结构相似性的定义逐渐变得更加严格。特别是,在层次结构的底部,节点之间的结构相似性只取决于它们的度,而在层次结构的顶部,相似性取决于整个网络(从节点的角度来看)。
- 为节点生成随机上下文,这些节点是结构相似的节点的序列,通过一个加权的随机漫步遍历一个多层图(而不是原始网络)可以观察到。因此,经常出现具有相似上下文的两个节点可能具有相似的结构。语言模型可以利用这种上下文来学习节点的潜在表示。
我们实现了一个struc2vec的实例,并通过一个例子和真实网络的数值实验,展示了它的潜力,和DeepWalk[16]、node2vec[6]、RolX[7]比较其性能。我们的结果表明,DeepWalk和node2vec未能捕捉到结构身份的概念,但struc2vec在这一任务中表现出色,即使原始网络受到强随机噪声(随机边缘去除)的影响。我们还证明了struc2vec在类分类任务中更优,在类分类任务中,节点标签更多地依赖于结构标识(例如,航空运输网络,标签代表机场活动)。
我们实现的一个实例struc2vec并通过数值实验显示其潜在的例子和实际网络,和DeepWalk[16]、node2vec[6]、RolX[7]比较其性能。
2. 相关工作
在欧几里得空间中嵌入网络节点在过去几十年里受到了不同社区的重视。该技术对于利用网络数据的机器学习应用程序很有帮助,因为节点嵌入可以直接用于类分类和集群等任务。
在自然语言处理[2]中,为稀疏数据生成密集的embedding向量具有悠久的历史。最近,Skip-Gram[12、13]提出了作为一个高效的技术去学习嵌入文本数据(例如,句子)。在其他属性中,学习到的语言模型将语义相似的单词放在空间中相邻的位置。
DeepWalk[16]首先提出了从网络中学习语言模型。它使用随机游走从网络中生成节点序列,然后用Skip-Gram把这些节点当作句子。直观地说,在网络中接近的节点往往具有相似的上下文(序列),因此它们的嵌入彼此很接近。这个想法后来被node2vec[6]扩展。node2vec提出了一个偏置的二阶随机游走模型,在生成顶点的上下文时提供了更多的灵活性。特别地,驱动有偏随机游走的边权值可以在一个矩阵映射图中被设计来同时捕获顶点同质性和结构等价性。然而,一个基本的限制是,如果结构上相似的节点的距离(跳数)大于Skip-Gram的窗口数,它们就永远不会共享相同的上下文。
subgraph2vec[14]是最近另一种学习子图嵌入的方法,与以前的技术不同,它不使用随机游走来生成上下文。另外,节点的上下文只是由它的邻居来决定。此外,subgraph2vec通过将具有相同局部结构的节点嵌入到空间中的相同点来获取结构等价性。尽管如此,结构等价的概念是非常严格的,因为它被定义为一个由Weisfeler - Lehman同构测试[21]决定的二元性质。因此,两个节点在结构上非常相似,并且没有重叠的邻居,在空间上可能并不相邻。
与subgraph2vec类似,最近对学习更丰富的网络节点表示方法进行了大量研究[4, 24]。然而,构建显式捕获结构的表示是struc2vec的重点。
最近一种仅使用网络结构显式标识节点角色的方法是RolX[7]。这种无监督方法的基础是枚举节点的各种结构特征,找出更适合这个联合特征空间的基向量,然后为每个节点分配一个分布在标识的角色(基)上,允许角色之间的混合成员关系。如果没有显式地考虑节点相似性或节点上下文(在结构方面),RolX很可能会遗漏在结构上等价的节点对。
3. STRUC2VEC
考虑获取网络中节点的结构标识的表示学习问题。一个成功的方法应该表现出两个期望的特性:
- 节点的潜在表示之间的距离应与它们的结构相似度密切相关。因此,两个具有相同局部网络结构的节点应该具有相同的潜在表示,而具有不同结构标识的节点应该相距较远。
- 潜在表示不应该依赖于任何节点或边缘的属性,包括节点标签。在结构上相似的节点应该有密切的潜在表示,独立于节点和边缘的属性。节点的结构身份必须独立于其在网络中的位置。、
考虑到这两个特性,我们提出了struct2vec,这是一个学习节点潜在表示的通用框架,由以下四个主要步骤组成:
(1)对于不同的邻域大小,确定图中每个顶点对之间的结构相似性。这在节点之间的结构相似性度量中引入了层次结构,提供了更多的信息来评估层次结构的每一层的结构相似性。
(2)构造一个加权的多层图,其中网络中的所有节点都存在于每一层中,每一层在测量结构相似度时对应于层次的一个层次。此外,各层内各节点对的权值与结构相似度成反比。
(3)使用多层图为每个节点生成上下文。特别地,在多层图上使用有偏随机游走来生成节点序列。这些序列可能包括结构上更相似的节点
(4)应用一种技术,从由节点序列给出的上下文中学习潜在表示,例如,Skip-Gram。
请注意,struct2vec是完全可以实现的,因为它不要求任何特定的结构相似性度量或表示学习框架。接下来,我们将详细解释struct2vec的每个步骤,并提供一种严格的方法来测量结构相似性。
3.1 测量结构相似
struct2vec的第一步是确定两个节点之间的结构相似性,而不使用任何节点或边缘。此外,这种相似性度量应该是层次化的,并且能够处理不断增加的邻域大小,从而捕捉到更多有关结构相似性的概念。直观地说,具有相同度的两个节点在结构上是相似的,但是如果它们的邻居也具有相同度,那么它们在结构上甚至更加相似。
令$G = (V,E)$代表顶点集$V$和的无向无权边集$E$的网络,其中$n = |V|$表示网络中的节点数,$k^*$是其直径。令$R_k(u)$代表在$G$中与$u$的距离(跳数)恰好为 $k \geq 0$的节点集。注意$R_1(u)$代表$u$的邻居,$R_k(u)$表示距离$k$的节点环。设$s(S)$为节点集合$S \subset V$的有序度序列。通过比较距离$u$和$v$为k处的环的有序度序列,我们可以建立一个层次结构来衡量结构相似性。其中,令$f_k(u,v)$表示在考虑其$k$跳邻域时,$u$和$v$之间的结构距离(距离小于等于$k$的所有节点以及它们之间的所有边)。定义如下:
其中$g(D_1,D_2) \geq 0$表示有序次序列$D_1$和$D_2$之间的距离,并且$f_{-1} = 0$。注意,根据定义,$f_k(u,v)$在$k$中不递减,只有当$u$或$v$在距离$k$处都有节点时才有定义。此外,在$f_k(u,v)$中使用距离为$k$的环,可以强制比较距离为$u$和$v$相同的节点的度序列。最后,注意如果$u$和$v$的$k$跳邻域是同构的,并且将$u$映射到$v$上,那么$f_{k-1}(u,v) = 0$。
最后一步是确定比较两个度序列的函数。注意,$s(R_k(u))$和$s(R_k(v))$可以是不同的大小,其元素是[0, n-1]范围内的任意整数,可能存在重复。我们采用动态时间规整(Dynamic Time Warping, DTW)来测量两个有序度序列之间的距离,该技术可以更好地处理不同大小的序列,并对序列模式进行松散比较[18,20]。
非正式地说,DTW是两个序列A和B之间的最优比对。给定一个距离函数$d(a, b)$,对于序列中的元素,DTW匹配每个元素$a \in A$到$b \in B$,使得匹配元素之间的距离之和最小。由于序列A和B的元素是节点的度数,我们采用以下距离函数:
注意当$a = b$时,$d(a,b) = 0$。因此,两个相同的有序度序列的距离为零。还要注意,通过取最大值和最小值的比值,1和2的度数比101和102的度数差得多,这是在测量节点度数之间的距离时所需的属性。最后,当我们使用DTW来评估两个有序度序列之间的相似度时,我们的框架可以采用任何其他的损失函数。
3.2 构建上下文图
我们构造了一个多层加权图来编码节点之间的结构相似性。设$M$表示用节点的$k$跳邻域表示$k$层的多层图。每一层$k = 0,…,k^*$是由具有节点集$V$的加权无向完全图构成的,因此,对于${n \choose 2}$条边,层中两个节点之间的边权值为:
请注意,只有在定义了$f_k(u,v)$的情况下才定义边,并且权重与结构距离成反比,并且假设值小于等于1,只有当$f_k(u,v)=0$时才等于1。注意,在结构上与$u$相似的节点在$M$的各个层上的权值更大。
我们使用有向边连接这些层,如下所示。每个顶点被连接到它在上面和下面层的相应顶点。因此,$k$层的每个顶点$u \in V$都与对应的$k + 1$层和$k - 1$层的顶点$u$相连。层间的边权重如下:
其中$\Gamma_k(u)$是与$u$关联的边数,其权值大于$k$层中完整图的平均边权值。特别低:
其中$\bar{w_k} = \sum_{(u,v) \in {V \choose 2}}w_k(u,v) / {n \choose 2}$。因此,$\Gamma_k(u)$度量$k$层中节点$u$与其他节点的相似度。请注意,如果当前层中有许多类似的节点,那么它应该更改层以获得更多的上下文。注意,向上移动一层,类似节点的数量只会减少。最后,log函数简单地减少了给定层中与$u$相似的大量节点的数量。注意$M$有$nk^*$个顶点,最多$k * {n \choose 2} + 2n(k^* - 1)$条加权边。
3.3 为节点生成上下文
使用多层图$M$为每个节点生成结构上下文$u \in V$。注意,$M$完全不使用任何标签信息来捕获$G$中节点之间的结构相似性。与之前的工作一样,struct2vec使用随机游走来生成节点序列,以确定给定节点的上下文。特别地,我们考虑一个有偏的随机游走,它在$M$附近移动,根据$M$的权值做出随机选择。在每一步之前,随机游走首先决定它是要改变层还是在当前层上行走(随机行走停留在当前层的概率为$q > 0$)。
假设它将停留在当前层,则在$k$层中从节点$u$到节点$v$的概率为:
其中$Z_k(u)$是在$k$层的节点$v$的归一化因子:
请注意,随机游走将更倾向于走到与当前顶点在结构上更相似的节点上,避免与它的结构相似度很低的节点。因此,一个节点$u \in V$的上下文可能具有结构上类似的节点,与它们的标签和它们在原始网络$G$中的位置无关。
存在概率为$1 - q$,随机游走决定改变层数,并以与边权值成正比的概率移动到$k + 1$层或$k - 1$层中相应的节点。特别是:
注意,每次在层中行走时,它都将当前顶点作为上下文的一部分,独立于层。因此,一个顶点$u$可能在第$k$层有一个给定的上下文(由这个层的结构相似度决定),但是在第$k + 1$层有这个上下文的一个子集,因为当我们移动到更高的层时,结构相似度不能增加。
最后,对于每个节点$u \in V$,我们在其相应的顶点在0层开始随机游走。随机漫步的长度固定且相对较短(步数),并且该过程重复一定次数,从而产生多个独立的随机游走结果(即,节点$u$的多个上下文)。
3.4 学习一个语言模型
最近的语言建模技术已经广泛地用于学习单词嵌入,并且只需要几组句子就可以生成有意义的表示。非正式地说,这个任务可以定义为学习给定上下文的单词概率。特别是,Skip-Gram[12]已被证明是有效的学习各种数据的有意义的表示。为了将其应用到网络中,可以使用人工生成的节点序列来代替句子。在我们的框架中,这些序列是由多层图$M$上的有偏随机游走产生的。给定一个节点,跳跃图的目标是最大化其在序列中上下文的可能性,其中一个节点的上下文由一个以其为中心的大小为$w$的窗口给出。
对于这项工作,我们使用Hierarchical Softmax。对于每个节点$v_j \in V$,Hierarchical Softmax在分类树中指定一条特定的路径,由一组树节点$n(v_j,1),n(v_j,2),…,n(v_j,h)$定义,其中$n(v_j,h) = v_j$,在这种情况下:
其中$C$是树中每个节点的二分类器。注意,因为分层Softmax操作的是二叉树,所以复杂度为$O(log|V|)$。
我们根据式(9)给出的优化问题来训练Skip-Gram。请注意,我们使用Skip-Gram来学习节点嵌入,任何其他学习文本数据潜在表征的技术都可以在我们的框架中使用。
3.5 复杂度和优化
为了构造M,必须计算每个层的每个节点对之间的结构距离,即对$u,v \in V$计算$f_k(u, v)$,且$0 \leq k \leq k^*$。然而,$f_k(u,v)$使用了两个度序列之间的DTW计算结果。而经典的DTW实现其复杂度为$O(\ell^2)$,存在复杂度为$O(\ell)$的快速技术,其中$\ell$是最大序列的大小。设$d_{max}$为网络中最大的度。对所有的节点$u$和层$k$,度序列的大小$|s(R_k(u))| \leq min(d_{max}^k, n)$。因为在每层中有${n \choose 2}$节点对,计算k层中所有距离的复杂度为$O(n^2 . min(d_{max}^k, n))$。最终的复杂度为$O(k * n^3)$。在接下来的部分中,我们将描述一系列的优化,这些优化将显著减少框架的计算和内存需求
减少度序列的长度(OPT1)。尽管k层的度序列的长度以$min(d_{max}^k, n)$为界,对于某些网络,即使$k$很小,这个长度也会很大(例如,对于$k = 3$,序列已经是$O(n)$)。为了降低比较大序列的成本,我们提出对有序度序列进行如下压缩。对于序列中的每个度,我们计算该度的出现次数。压缩的有序度序列是一个包含度和出现次数的元组。由于网络中的许多节点往往具有相同的度,因此在实践中,压缩后的有序度序列可以比原来的有序度序列小一个数量级。
设$A^{‘}$和$B^{‘}$分别表示$A$和$B$的压缩度序列。由于$A^{‘}$和$B^{‘}$的元素是元组,所以我们采用了如下函数计算DTW距离:
其中$a = (a_0, a_1)$和$b = (b_0, b_1)$是在$A^{‘}$和$B^{‘}$中的元组,$a_0$和$b_0$是度,$a_1$和$b_1$是出现的次数。注意,使用压缩的度序列会导致具有相同度的原始序列片段之间的比较(而不是比较每个度)。因此,由式(10)可以得到原始度序列上的DTW的近似值,如式(2)所示。
减少成对相似度计算的数量(OPT2)。当原始框架在每一层$k$评估每个节点对之间的相似性时,显然这是不必要的。考虑两个度非常不同的节点(例如,2和20)。他们的结构距离即使在$k=0$时也是非常大的。因此,在$M$中它们之间的边的权重非常小。因此,当对这些节点创建上下文时,随机游走不太可能走过这条边,故在$M$中没有这条边并不会显著地改变模型。
我们限制对于每一层$k$中节点的成对相似度计算的数量到$O(log(n))$。设$J_u$代表在$M$中与$u$相邻的节点集合,每一层都是一样的。$J_u$的节点结构应该与$u$是最相似的。为了确定$J_u$,我们取与$u$度最相似的节点。这可以通过对网络中所有节点的有序度序列(对于节点$u$的度)进行二叉搜索,并在搜索完成后的每个方向上取$log n$个连续的节点来方便地计算出来。因此,计算所有节点的$J_u$有$O(nlog(n))$的复杂度。至于内存需求,$M$的每一层现在都有$O(nlog(n))$条边,而不是$O(n^2)$。
减少层数(OPT3)。$M$中的层数由网络的直径$k^*$给出。然而,对于许多网络来说,直径可能远远大于平均距离。此外,评估两个节点之间的结构相似性的重要性随着$k$值的增大而降低。特别的,当$k$接近$k^*$时,环上的度序列$s(R_k(u))$长度也会变得相对较短,因此$f_k(u,v)$与$f_{k-1}(u,v)$相差不大。因此,我们将$M$中的层数限制为$k^{‘} < k^*$,以获取用于评估结构相似性的最重要的层数。这显著减少了构造$M$的计算和内存需求。
4. 试验
4.1 杠铃图(Barbell Graph)
我们将$B(h,k)$表示为$(h,k)-barbell$图,它由两个完全图$K_1$和$K_2$(每个图有$h$个节点)组成,由一个长度为$k$的路径图$P$连接。两个节点$b_1 \in V(K_1)$和$b_2 \in V(K_2)$代表桥梁。使用$\{p_1, …, p_k\}$表示$V(P)$,我们将$b_1$连接到$p_1$,$b_2$连接到$p_k$,从而将三个图连接起来。
Barbell Graph具有相同结构标识的节点数目。设$C_1 = V(K_1) / \{b_1\}$和$C_2 = V(K_2) / \{b_2\}$,注意$v \in \{C_1 \cup C_2\}$是结构上等价的,任何一对这样的节点之间都存在自同构。此外,我们还有所有的节点对$\{p_i, p_{k-i}\},1 \leq i \leq k-1$,与$\{b_1, b_2\}$在结构上是等同的。图2展示了一个$B(10, 10)$图,结构等效节点有相同的颜色。
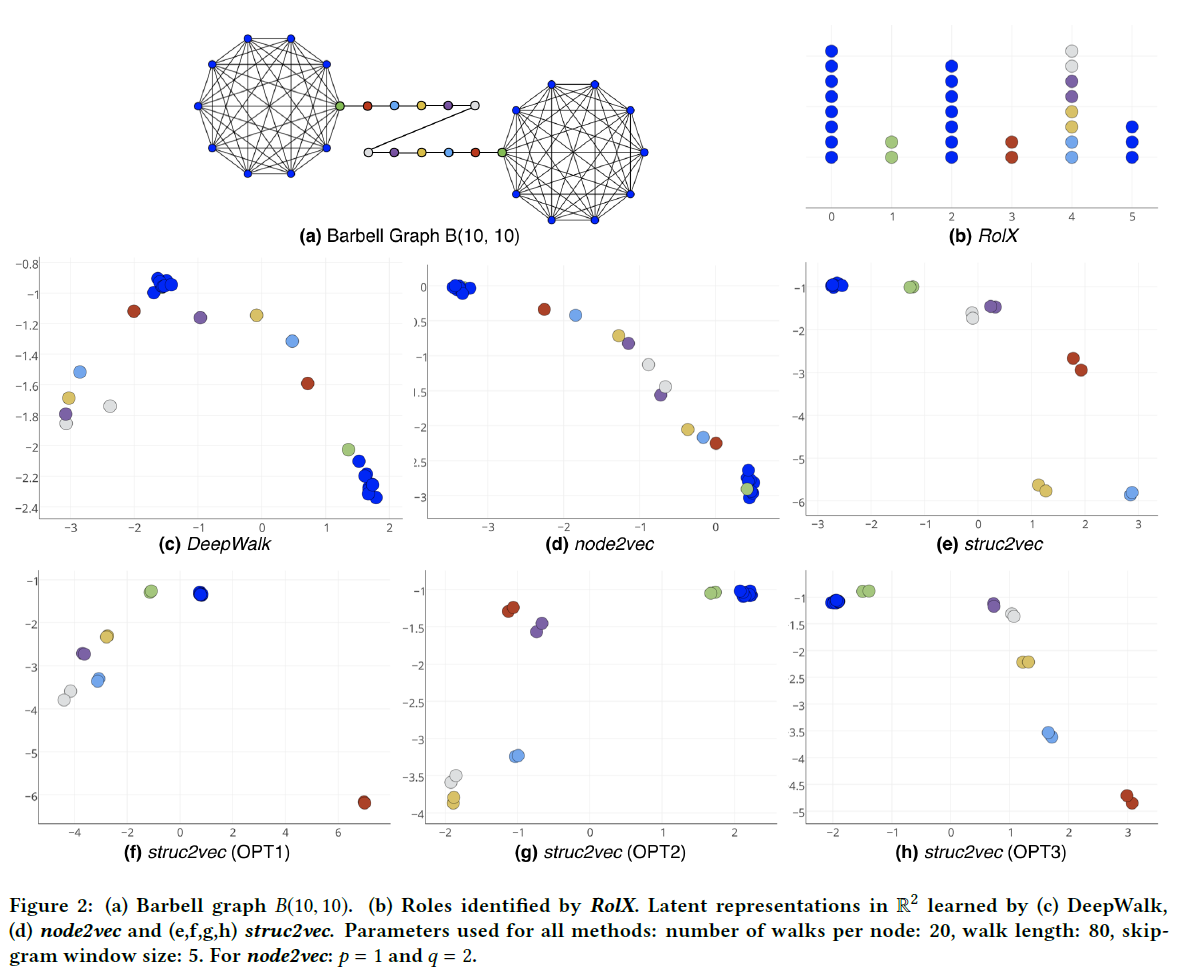
因此,我们期望struct2vec学习顶点表示来获得上面提到的结构等价性。每个在结构上等价的节点对都应该具有类似的潜在表示。此外,学习表示还应该捕获结构层次:虽然节点$p_1$并不等同于节点$p_2$或节点$b_1$,但我们可以清楚地看到,从结构的角度来看,它更类似于$p_2$。
根据图2,DeepWalk没有捕捉到结构上的等价,这是意料之中的,因为它没有考虑到结构上的等价。即使node2vec的参数$p$和$q$有不同的变化,它也不能捕获结构标识。实际上,它学习的主要是图的距离,将更近的节点放在图中更近的潜在空间节点上。node2vec的另一个限制是,Skip-Gram的窗口大小使得$K_1$和$K_2$中的节点不可能出现在相同的上下文中。
另一方面,struct2vec学习正确分隔相同类的表示,将在结构上等价的节点放在彼此附近的潜在空间中。注意,相同颜色的节点紧密地分组在一起。此外,$p_1$和$p_10$被放置在$K_1$和$K_2$的节点附近,因为它们是桥梁。最后,请注意,这三种优化对表示的效果没有任何影响。实际上,在OPT1下的潜在表示中,结构上等价的节点之间的距离更近。
最后,我们将$RolX$应用于杠铃图(图2(b))。总共确定了6个角色,其中一些角色确实精确地捕获了结构等价性(角色1和角色3)。然而,在结构上等价的节点(在$K_1$和$K_2$中)被放置在三个不同的角色中(角色0、角色2和角色5),而角色4包含路径中所有剩余的节点。因此,尽管在向节点分配角色时,RolX确实捕获了一些结构等价的概念,但struct2vec更好地识别和分离了结构等价。
4.2 空手道网络(Karate Network)
空手道俱乐部[25]是一个由34个节点和78条边组成的网络,其中每个节点代表一个俱乐部成员,边表示两个成员在俱乐部外互动。在这个网络中,边缘通常被解释为成员之间友谊的象征。
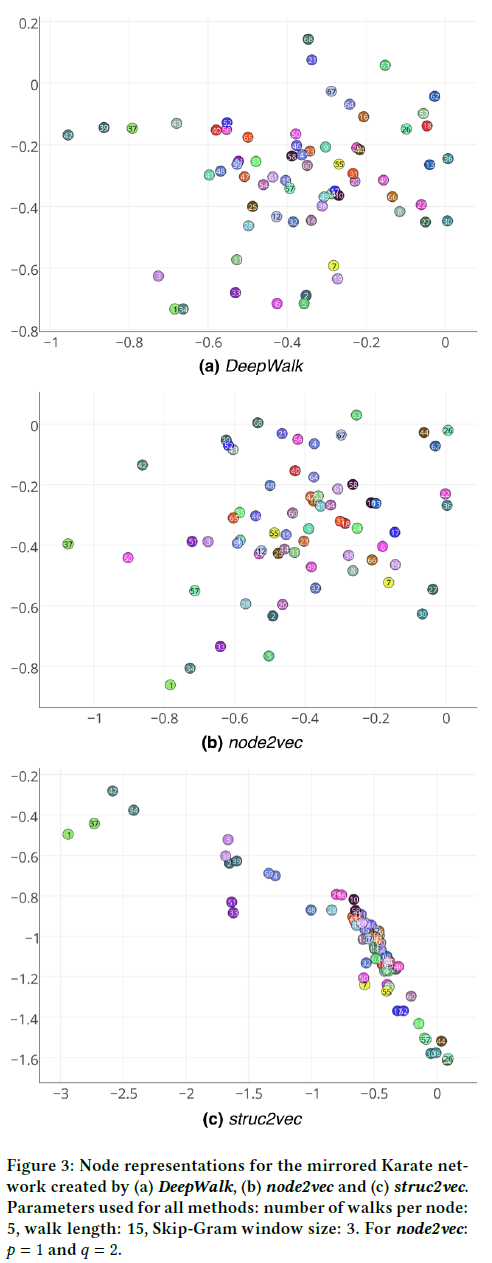
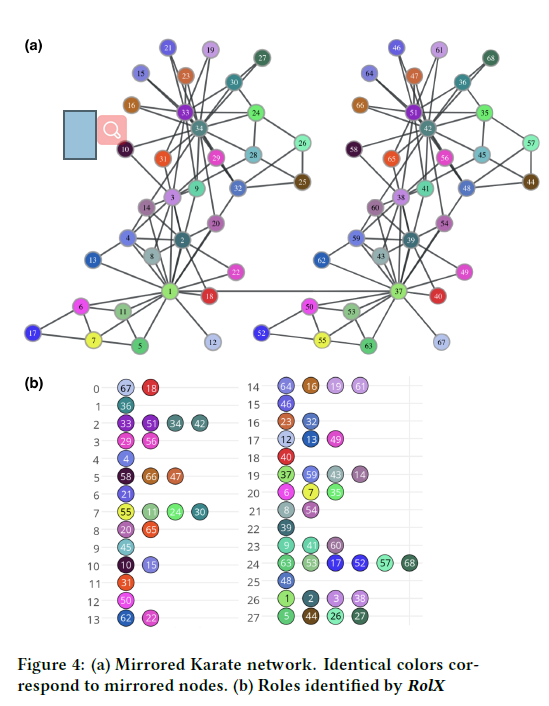
我们构建一个网络组成的两个副本的$G_1$和$G_2$,其中每个节点$v \in V(G_1)$都有一个镜像节点$u \in V(G_2)$。我们还通过在镜像节点1和37之间添加一条边来连接两个网络。尽管这对于我们的框架来说不是必需的,但是DeepWalk和node2vec不能将图的不同连接组件放在相同的上下文节点中。因此,为了与两个基线进行更公平的比较,我们添加了边。图4a展示了具有相同颜色对应对的镜像网络。
图3展示了通过DeepWalk,node2vec和struct2vec学习的潜在表示,显然,Deepwalk和node2vec并没有在潜在空间中得到结构上等价的节点,包括镜像节点。
同样,struct2vec设法学习能够正确捕获节点的结构标识的特性。镜像对-在潜在空间中有相同颜色的节点-保持紧密的联系,在表示的组合方式上有一个复杂的结构层次。
例如,请注意节点1、34及其对应的镜像(37和42)在潜在空间中处于单独的集群中。有趣的是,这些节点恰恰代表了俱乐部教练Hi先生和他的管理员John A。网络由两个节点组成,节点1和节点34分别以Mr. Hi和John A为中心,将俱乐部成员分成两组。请注意,struct2vec捕获了它们的函数,尽管它们之间没有边界。
潜伏空间内另一可见簇由节点2,3,4和33,还有他们的镜像节点。这些节点在网络中也具有特定的结构标识:它们都具有较高的度,并且还与至少一个中心相连。最后,节点26和节点25(在潜在空间的最右边)具有非常接近的表示,这与它们的结构作用相一致:它们的度都很低,距离节点34有2跳的距离。
注意,节点7和节点50(粉色和黄色)被映射到潜在空间中的闭合点。令人惊讶的是,这两个节点在结构上是等价的。可以更容易地看到一旦节点6和7也结构等效,和节点6的镜像节点50也结构等效。
最后,图4b显示了$RolX$在镜像空手道网络中标识的角色(标识了28个角色)。注意,1和34被置于不同的角色。1的镜像(节点37)也被放置在不同的角色中,而34的镜像(节点42)被放置在与34相同的角色中。总共有7对对应的配对被置于相同的角色。然而,一些其他的结构相似点也被识别出来,例如,节点6和节点7在结构上是等价的,并被分配了相同的角色。同样,RolX似乎捕获了网络节点之间结构相似性的一些概念,但struct2vec可以通过潜在表示来识别和分离结构等价。
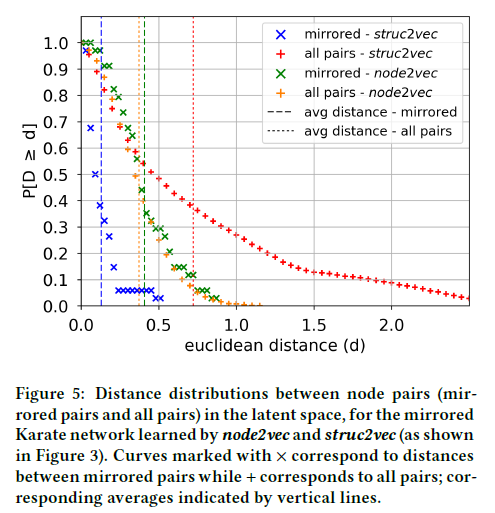
考虑节点的潜在表示之间的距离。我们度量对应于镜像节点的对之间以及所有节点对之间的距离分布(使用图3所示的表示)。图5显示了node2vec和struc2vec学习的表示的两个距离分布。对于node2vec,这两个分布实际上是相同的,这表明镜像对之间的距离与所有对之间的距离很好地融合在一起。struc2vec有两个非常不同的分布:94%的镜像节点对的距离小于0.25,而所有节点对中的68%的距离大于0.25。而且,所有节点对之间的平均距离比镜像节点对的平均距离大5.6倍,而对于node2vec来说,这个比例略小于1。
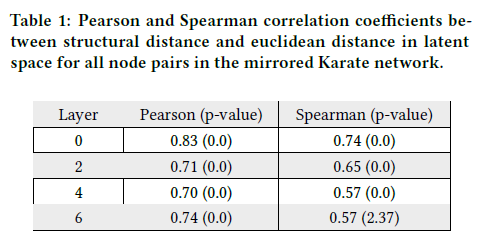
为了更好地描述struc2vec学习的潜在表示中结构距离和距离之间的关系,我们计算了所有节点对的两个距离之间的相关性。特别地,对于每一层$k$,我们计算$f_k(u,v)$之间的Spearman和Pearson相关系数,如公式(1)所示,以及学习表示中$u$和$v$之间的欧氏距离。表1所示的镜像空手道网络的结果确实证实了两个距离之间存在很强的相关性,对于每一层,这两个系数都能捕捉到。这表明,struc2vec确实在潜在空间中捕获了该方法所采用的结构相似性测度。
4.3 边缘去除的鲁棒性
我们说明了在噪声存在时,该框架在表征结构特性方面的潜力。特别是,我们从网络中随机删除边,直接改变其结构。我们采用简约的边缘采样模型来实例化两个结构相关的网络[15]。该模型的工作原理是取一个固定的图$G = (V,E)$通过对每条边$e \in E$以概率$s$进行采样,生成一个图$G_1$。因此,$G$中的每条边以概率$s$在$G_1$中存在。使用$G$重复此过程以生成另一个图$G_2$。因此,$G_1$、$G_2$是结果相关的的,$s$控制结构相关量。注意当$s=1$时,$G_1$和$G_2$是同构的,当$s=0$时,所有结构消失。
我们将边缘采样模型应用于从Facebook(224个节点,3192条边,最大度99,最小度1)[10]中提取的egonet,生成不同$s$值的$G_1$和$G_2$。我们重新标记$G_2$中的节点(以避免相同的标签),并将两个图的并集作为框架的输入网络。注意,这个图至少有两个连接的组件(对应于$G_1$和$G_2$),每个节点(在$G_1$中)都有一个对应的组件(在$G_2$中)。
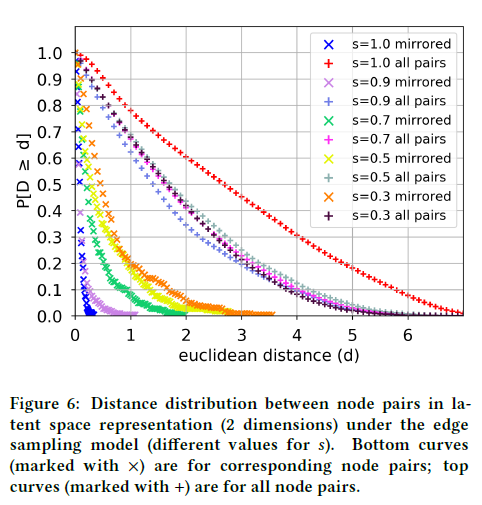
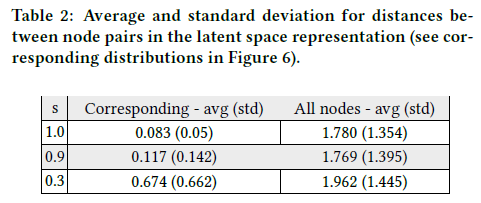
图6为$s$各值对应的节点对与所有节点对之间的距离分布(对应的平均值如表2所示)。对于$s = 1$,两种距离分布存在显著差异,所有对的平均距离是对应对的21倍。更有趣的是,当$s = 0.9$时,这两个分布仍然非常不同。注意,进一步减小$s$对所有对的距离分布影响不大,但会缓慢增大对应对的分布。然而,即使$s = 0.3$(即原始边同时出现在G1和G2中的概率为0.09,$s^2$),该框架仍将相应的节点更靠近潜空间。实验表明了该框架的鲁棒性,即使存在结构噪声,也能揭示节点的结构特征。
4.4 分类
网络节点潜在表示的一个常见应用是分类。当节点的标签更多地与它们的结构标识相关,而不是与相邻节点的标签相关时,可以利用struc2vec完成此任务。为了说明这种可能性,我们考虑空中交通网络:未加权的、无定向的网络,其中节点对应于机场,边表示商业航班的存在。机场将被分配一个与他们的活动水平相对应的标签,以航班或人员来衡量(下面讨论)。我们考虑以下数据集:
- 巴西空中交通网络: 收集自国家民航局(ANAC)从2016年1月至12月的数据。该网络有131个节点,1038条边(直径为5)。
- 美国空中交通网络: 收集自美国运输统计局2016年1月至10月的数据。网络有1190个节点,13599条边(直径为8),机场活动以同期通过(到达+离开)机场的总人数来衡量。
- 欧洲空中交通网络: 收集自2016年1月至11月的欧盟统计局的数据。网络有399个节点,5995条边(直径为5),机场活动以同期的总起降次数来衡量。
对于每个机场,我们为它们的活动分配四个可能的标签之一。特别是对于每个数据集,我们使用从经验活动分布中获得的四分位数将数据集分为四组,并为每个组分配不同的标签。在美国,标签1是给25%不太活跃的机场,等等。注意,所有的类(标签)都具有相同的大小(机场的数量)。
我们使用struc2vec和node2vec学习每个空中交通网络节点的潜在表示,使用网格搜索为每个案例选择最佳超参数。注意,此步骤不使用任何节点标签信息。每个节点的潜在表示成为训练监督分类器的特征。我们也只考虑节点度作为一个特征,因为它捕获了结构身份的一个非常基本的概念。最后,由于类的大小相同,所以我们只使用准确性来评估性能。使用随机样本重复实验10次来训练分类器,报告其平均性能。
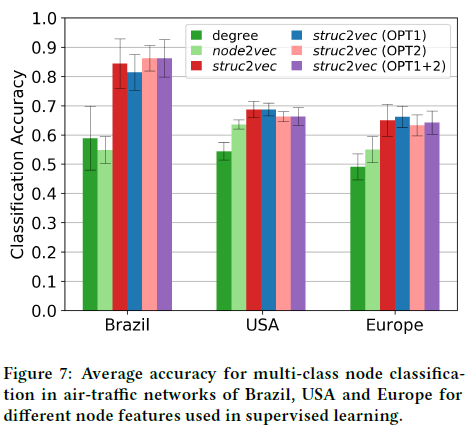
图7显示了所有空中交通网络不同特征的分类性能。显然,struc2vec优于其他方法,而且它的优化具有很强的实用性。对于巴西的网络,struc2vec比node2vec提高了50%的分类精度。有趣的是,对于这个网络,node2vec的平均性能(略)低于节点度,这表明了节点的结构身份在分类中的重要性。
4.5 可扩展性
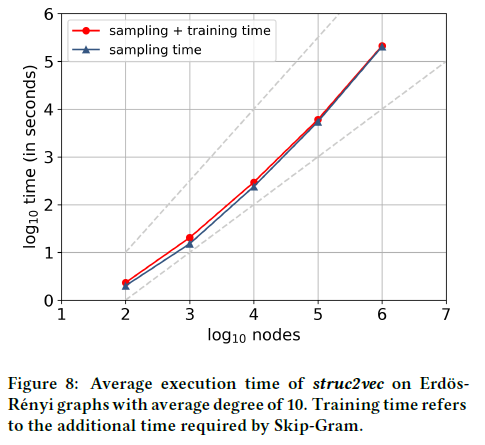
为了说明它的可扩展性,我们对Erdos-Renyi随机图模型的实例应用了优化的struc2vec(使用128维、每个节点十次游走、行走长度80、Skip-Gram窗口10)。我们计算了在大小为100到1,000,000个节点和平均度为10的图上运行10次独立运行的平均执行时间。为了加快对语言模型的训练,我们使用了带负采样[13]的Skip-Gram。图8显示了执行时间(以log-log比例表示),表明struc2vec的比例是超线性的,但更接近于线性,而不是$n^{1.5}$(虚线)。因此,尽管struc2vec在最坏情况下具有时间和空间复杂性,但实际上它可以应用于非常大的网络。
【Graph Embedding】struc2vec