【Graph Embedding】line
关于Graph Embedding系列的论文翻译解读文章:
参考资料
paper: https://arxiv.org/pdf/1503.03578.pdf
code: https://github.com/tangjianpku/LINE
摘要
文章同样是研究如何将网络如何嵌入到低维向量空间的问题,应用于可视化,节点分类,和链路预测上。这种新型网络表征方法称为LINE,适用于任意类型的信息网络(有向的,无向的,以及无权的有权的)。该方法优化了一个精心设计的目标函数,保留了局部以及全局的网络结构。提出了一种边采样算法,该算法解决了经典随机梯度下降的局限性,并提高了推理的有效性和效率。经过实验验证了LINE在多种真实世界的信息网络(语言、社会,引文)的有效性,该算法非常有效,能够在典型的单台机器上学习在几小时内嵌入具有数百万个顶点和数十亿个边的网络。
1. 介绍
为了更好的在嵌入过程中保留网络中的拓扑结构信息(保留节点之间的关联关系)。LINE提出了一阶相似度和二阶相似度的概念。
一阶相似度指顶点之间直接连接信息。在真实网络数据中不足以用于保留全局的网络结构。故补充了二阶相似度的概念(即具有共享的邻居节点的顶点可能是相似的)。在社会学和文本语库中可以找到这样的推论。社交网络中,两个人的好友关系的重复度越高,两个人的相关性就越高。文本语料库中,我们可以通过一句话的其他内容来了解单个单词的意思。事实上,有许多共同好友的两个人大概率有相似的爱好并可能成为朋友,而常与同样的语句组合使用的单词更可能具有相同的意思。
LINE提出了一种保留了一阶相似度和二阶相似度的精心设计的目标函数。直接对真实信息网络使用随机梯度下降是不可取的。因为许多网络中的边是带权的,且权重呈现了高度的差异性。对于一个单词共现网络,单词对的权重变化可能从一到百到千,边的权重乘以梯度会引起梯度爆炸,进而影响性能。为了解决这个问题,LINE用与其权重成比例的概率对边进行采样,并将采样边视为二进制边以进行模型更新。在这样的取样过程下,目标函数不会发生变化, 且边的权重不再影响梯度。
LINE的贡献如下三点:
- LINE适用于任意类型的信息网络,并能够轻易拓展到百万个节点。它拥有一个可以保留一阶相似度和二阶相似度的目标函数。
- 提出了一种边采样算法以优化目标函数。该算法解决了经典随机梯度下降的局限性,提高了推理的有效性和效率。
- 在真实的信息网络中继续了广泛的实验。实验结果证明了LINE模型的有效性和效率。
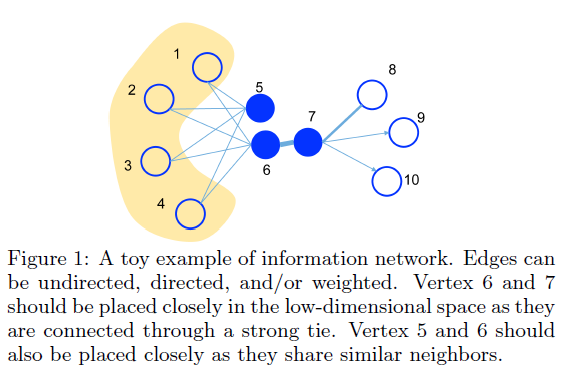
2. 相关工作
经典的图表征方法和降维方法使用数据点的特征向量来创建关联图。最近的文献介绍了图矩阵分解方法,使用优化的随机梯度下降方法进行了矩阵分解。该方法不能保留网络全局结构,并且只能应用于无向图。还有之前结束的DeepWalk。DeepWalk为获取更高阶的节点产生相似的低维表示,使用DFS随机游走对图进行节点采样,但没有提供一个明确的目标函数。而LINE使用了BFS的策略。此外,DeepWalk只能应用到无权的网络,而LINE可以应用于包含有权/无权的边的网络。
3. 问题定义
定义1 信息网络
信息网络被定义为$G = (V, E)$,其中$V$表示节点集合,每个节点表示一个数据对象。$E$表示节点间的边。每一个$e \in E$都是一个有序对 $e = (u, v)$且都有一个关联的权重$w_{uv} > 0$。如果$G$是无向图,那么有$(u, v) \equiv (v, u)$且$w_{uv} \equiv w_{vu}$。如果$G$是有向图,则$(u, v) \not\equiv (v, u)$且$w_{uv} \not\equiv w_{vu}$。
定义2 一阶相似度
一阶相似度:一阶相似度是网络中两个节点的局部相似度。若节点$u$和$v$之间有边$(u,v)$,则$w_{uv}$表示$u$和$v$之间的一阶相似度。如果$u$和$v$之间没有可以观察的边,一阶相似度则为0。
定义3 二阶相似度
二阶相似度:网络中一对节点$(u, v)$之间的二阶相似度是他们相邻网络结构的相似度。数学化的定义,使$[p_{u} = (w_{u,1},… ,w_{u,|V|})$ 描述节点$u$与其他节点的一阶相似度,那么$u$与$v$的二阶相似度取决于$p_u$与$p_v$之间的相似度。如果没有从$u$到$v$连接(或从$v$到$u$)的中间节点。则$u$和$v$之间的二阶相似度为0。
定义4 大规模信息网络embedding
大规模信息网络embedding: 给定一个大型网络$G=(V, E)$,大规模信息网络嵌入的目标是把每个节点$u \in V$ 嵌入到低维向量空间$R^{d}$中。如:学习一个函数$f_{G}:V\to R^{d},d\ll |V|$。在$R^{d}$空间内,节点间的一阶相似度和二阶相似度都被保留。
4. LINE:大规模信息网络嵌入
真实世界网络下的一个理想的嵌入模型必须满足如下几个条件:1.保留一阶相似度和二阶相似度。2.能够支持含有百万节点和亿万边的大型网络的规模。3.能够处理任意类型的边(有无方向,有无权重)。
4.1 模型描述
分别描述保持一阶近似和二阶近似的线性模型,然后介绍一种将两种近似结合起来的简单方法。
4.1.1 LINE的一阶相似度
对于无向边$(i, j)$, 我们定义$v_i$和$v_j$的相连的可能性如下:
其中,$\vec u_i\in R^d$ 是$v_i$ 节点的低维向量表示。$p(.,.)$是 $V*V$ 的向量空间下的一个分布,它所验证的概率可以被定义为$\hat p_1(i,j)=\frac{w_{ij}}{W}$,其中$W=\sum_{i,j\in E}w_{ij}$
为了保留一阶相似度,可以直接最小化以下目标函数:
其中$d$是两个分布的距离,我们选择最小化两个可能分布的KL距离 (KL距离:$KL(p||q)= \int p(x)log\frac{p(x)}{q(x)}dx = -\int p(x)log\frac{q(x)}{p(x)}dx$ 用于衡量两个概率分布的差异情况, 其值越大说明两个分布的差异越大)。使用KL距离来替换d(.,.)并忽略一些约束。我们得到了:
注意:该一阶相似度仅应用于无向图,而非有向图。通过寻找能够使(3)式最小化的$\{\vec u_i\}_{i=1..|V|}$ 。我们可以在$d$维的空间里表示每个节点。
4.1.2 LINE的二阶相似度
二阶相似度可以应用于有向图以及无向图。给定一个网络,为不失一般性,我们假设它是有向的(无向边可以被视为两个方向相反、权重相等的有向边)。每个顶点既是顶点本身,也是其他顶点的上下文。在这种情况下,每个顶点也被视为一个特定的”上下文”,在“上下文”中具有相似分布的顶点被认为是相似的。因此,每个顶点扮演两个角色:顶点本身和其他顶点的一个特定“上下文”。所以提出两个向量$\vec u_i$和$\vec u_i^\prime$,其中$\vec u_i$代表点\vec v_i$作为一个顶点时的表示,而$\vec u_i^\prime$代表其作为一个特定的”上下文”时的表示。对于每条有向边$(i, j)$,定义由顶点$v_i$生成的特定”上下文”$v_j$的概率为:
其中,$|V|$是顶点或上下文的数量。对于每个顶点$v_i$,(4)式定义了一个上下文的条件分布$p_2(\cdot|v_i)$,例如网络中节点的完整集合。为了保留二阶相似度,我们应该使用低维表征的上下文条件分布$p_2(\cdot|v_i)$ 接近于经验分布$\hat p_2(\cdot|v_i)$ 。这样,我们最小化了以下目标函数:
其中$d(.,.)$是两个分布之间的距离。由于顶点在网络中的重要性不同,我们引入了$\lambda_i$ 到目标函数中来表示网络中顶点$i$的重要性,可以通过度来计算得到或者通过PageRank算法来评估。经验分布$\hat p_2(\cdot|v_i)$ 被定义为$\hat p_2(v_j|v_i)=\frac{w_{ij}}{d_i}$ ,其中$w_{ij}$是边$(i, j)$的权重,且$d_i$是顶点$i$的出度。即,$d_i=\sum_{k\in N(i)}w_{ik}$ . 其中$N(i)$是$v_i$节点的“出”邻居(从$i$节点出发的邻节点),在本文中,为了方便,我们设置$\lambda_i$ 作为顶点$i$的出度。$\lambda_i=d_i$,我们还采用KL散度作为距离函数,使用KL距离代替d(.,.).设置$\lambda_i=d_i$并忽略约束,我们得到了:
通过学习能够使以上目标函数最小化的$\{\vec u_i\}_{i=1..|V|}$ 和 $\{\vec u_i\prime\}_{i=1..|V|}$,我们能够通过一个$d$维的向量$\vec u_i$表示每个顶点$v_i$。
4.1.3 结合一阶相似度和二阶相似度
文章分别保留一阶相似度和二阶相似度,然后,为每个顶点连接由两种方法训练得到的embedding。 更好的方法是结合两个相似度来联合训练目标函数(3)和(6)。
4. 2 模型优化
优化目标函数(6)的计算代价昂贵,在计算条件概率$p2(\cdot|v_i)$ 时需要对整个顶点集求和。所以采用了论文[13]中提出的负采样方法,根据每个边$(i,j)$的一些噪声分布对多个负边进行采样,它为每个边指定了以下目标函数:
其中$\sigma(x)= 1/exp(-x)$ 是sigmoid函数。第一项对观察到的边进行建模,第二项对从噪声分布中绘制的负边进行建模,而$K$是负边的数量。我们根据[13],设置$p_n(v)\propto d_v^{3/4}$ ,其中$d_v$是$v$节点的出度。
为了(3)式的目标函数。存在一个平凡解:$u_{ik}=\infty$。其中$i=1,…,|V|$且 $k=1…,d$。为了避免平凡解,我们仍然可以使用负采样方法,仅将$\vec u_{j}\prime^T$变成$\vec u_j^T$。
我们采用了异步随机梯度算法(ASGD)来优化等式(7)。在每一步,ASGD算法取样了一小部分的边并更新了模型的参数,如果边$(i,j)$被取样,那么关于$i$节点的embedding向量$\vec u_i$的梯度可以被计算:
这样的梯度将乘以边的权重。当边的权重具有高方差时,这将成为问题。例如,在单词共现网络中,有些单词共现的次数上千,有些次数非常少。在这样的网络中,梯度的规模偏差太大,难以寻找一个好的学习比例。如果我们根据有较小权重的边来选择一个大的学习比率,权重较大的边的梯度会爆炸。如果根据较大权重的来选择一个小的学习比率,权重较小的边的梯度会太小。
4.2.1 边采样算法优化
一个简单的方法是将一条带权的边展开为多种二进制边。例如,一个权重为$w$的边展开为$w$个二进制边。这样能够解决问题但增加了内存需求,尤其是在边的权重值非常大时。LINE从原始边进行取样,并将取样的边视为二进制边。采样概率与原始边的权重成比例。通过这种边采样处理,总体目标函数保持不变,问题归结为如何根据权重对边进行采样。
令$W=(w_1,w_2,w_3,…,w_{|E|})$表示边的权重的顺序。一种简单的方法是可以直接计算权重的总和 $w_{sum}=\sum_{i=1}^{|E|}w_i$,然后在$[0,w_{sum}]$中取一个随机值来看随机值落入的区间$[\sum_{j=0}^{i-1}w_j,\sum_{j=0}^iw_j]$。这个方法得到样本的时间复杂度时$O(|E|)$。当边的数量$|E|$较大时开销较大。LINE根据复杂度仅为O(1)的alias table(别名表)[9]方法来取样。
从alias table中取样一条边的时间O(1),优化一个负采样需要$O(d(K+1))$的时间,其中$K$是负样本的数量。因此,总体每一步骤都需要$O(dK)$时间。在实践中,我们发现用于优化的步骤数量与边的数量$O(|E|)$成比例。因此,LINE的总的时间复杂度是$O(dK|E|)$,与边$|E|$的数量呈线性关系的,且不依赖于顶点数量$|V|$。这种边取样方法在不影响效率的情况下提升了随机梯度下降算法的有效性。
4.3 讨论
低度顶点
第一个问题:如何精确嵌入具有较低度数的顶点?由于这类顶点的邻居数量很少,所以难以得到它所对应的精确表征,尤其是严重依赖上下文的二阶相似度。一种推论是,通过增加其高阶的邻居(如邻居的邻居)来拓展这些顶点的邻居。在LINE中,仅讨论增加二级邻居。即对每个顶点,增加其邻居的邻居。顶点$i$和其二级邻居节点$j$之间的距离可以被计算为:
实际上,可仅为具有较低度数的顶点$i$增加一个有最大相似度$w_{ij}$的顶点子集${j}$。
新的顶点
第二个问题:如何得到新顶点的表征?对于一个新顶点$i$,如果已知它与已存在的顶点之间连接。我们可以根据已存在的顶点获得经验分布$\hat p_1(\cdot ,v_i)$和$\hat p_2(\cdot|v_i)$。为了获取新顶点的嵌入,根据目标函数(3)式和(6)式。一个直接的方法通过更新新顶点的嵌入并保持已存在顶点的嵌入来最小化以下任意一个目标函数:
5. 试验
5.1 试验设置
数据集
- 语言网络
- 社交网络
- 引用网络
算法比较
与一些可以处理大规模网络的几种图嵌入方法进行比较。
- Graph Factorization(GF): 一个信息网络可以被表示为一个相似矩阵(affinity matrix),通过矩阵分解可以得到每个顶点的低维向量表示。图分解算法经过随机梯度下降的优化可以用于处理大规模网络,但它仅应用于无向网络。
- DeepWalk
- LINE-SGD: 通过随机梯度下降优化了等式(3)和(6)的LINE模型。该方法中模型更新时取样的边的权重直接与梯度相乘。该方法有两个变量:LINE-SGD(1st)和LINE-SGD(2nd),分别使用了一阶相似度和二阶相似度。
- LINE:经过了边取样处理优化后的LINE模型。在每一个随机梯度下降的步骤,边会根据与权重成比例的可能性被取样,然后取样所得到的边在模型更新中按二进制边处理。与GF类似,LINE(1st)和LINE-SGD(1st)仅应用于无向图。LINE(2nd)和LINE-SGD(2nd)可以应用于有、无向图。
- LINE(1st+2nd): 为了同时利用一阶相似度和二阶相似度,一种简单直接的方法是将通过LINE(1st)和LINE(2nd)学习到的表征向量串联得到一个长向量。串联之后,维度应该被重新加权以平衡两种表征。在一个有监督的学习任务中,维度的权重可以基于训练数据被自动得到。在无监督的学习任务重,很难去设置权重值,因此仅将LINE(1st+2nd)应用到有监督任务。
参数设置
所有方法的小批量随机梯度算法(mini-batch SGD)的规模被设置成1。(每次只用总训练集的一小部分来训练,loss的下降更稳定,占用资源更少)。与论文[13]相同,学习速率的初始值被设置成$\rho _0=0.025$且$\rho _t=\rho _0(1-t/T)$.其中$T$是mini-batch或边样本的数量,为了公平的对比,语言网络的嵌入维数设置为200,与单词嵌入时使用的一样。对于其他网络,默认的维数是128,与论文[16]中使用的一样。其他默认设置包含:LINE和LINE-SGD的负样本数量$K=5$。LINE(1st)和LINE(2nd)的样本总数T=100亿,GF的T=200亿,窗口大小$win=10$,步长$t=40$。DeepWalk中每个节点的步数$\gamma=40$。所有嵌入向量通过令$||\vec w||_2=1$最终正则化。
5.2 定量结果
5.2.1 语言网络
单词分析和文本分类的应用场景被用于评估学习嵌入的有效性。
(一)单词分析
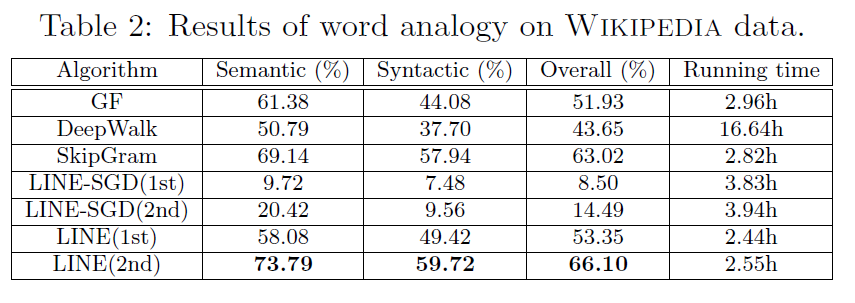
给定单词对$(a,b)$和单词$c$,目标是找到一个$d$使得$ab$之间的关系与$cd$之间的关系是相同的。给定一个单词的嵌入,目标是找到一个单词$d^{*}$,其嵌入与向量$\vec u_b-\vec u_a+\vec u_c$余弦接近。即,$d^{*}=argmax_dcos((\vec u_b - \vec u_a+ \vec u_c), \vec u_d)$。任务中的单词分析包括语义分析和句法分析。表2展示了对维基百科网络应用网络嵌入的单词分析结果。对于GF,单词对之间的权重被定义为共现次数的对数,比直接定位为共现次数的性能表现更好。对于DeepWalk,将语言网络转换为二进制网络过程中尝试使用不同的截断门槛,当所有的边都保留在网络中时能够获得最好的性能。
我们可以看到LINE(2nd)的表现优于其他方法,包括Skip-Gram。这表示了二阶相似度能够比一阶相似度更好的获取单词语义。这并不意外,高的二阶相似度意味着两个单词能够在同样的上下文中相互替换。意外的是,LINE(2nd)的表现甚至优于Skip-Gram。原因可能是语言网络比单词序列能够更好的捕获全局的单词共现结构。其他方法中,GF和LINE(1st)表现显著优于DeepWalk,即使Deepwalk拓展了二阶相似度,这可能是因为Deepwalk忽略在语言网络中非常重要的边权重。通过SGD优化的LINE模型表现比较差,因为,语言网络的边的权重的偏差范围较大,可能从1-1万,影响了学习。使用经过边取样处理优化的LINE模型能够较好处理以上问题,使用了一阶相似度和二阶相似度的表现的尤其好。
所有的方法都运行在一个单个机器(1T内存,40个20Ghz、16个线程的CPU内核)。LINE(1st)和LINE(2nd)都非常有效,处理2百万节点和十亿条边的网络仅需要不到3个小时。两者都比图分解方法快至少10%,比DeepWalk方法快了5倍。
(二)文件分类
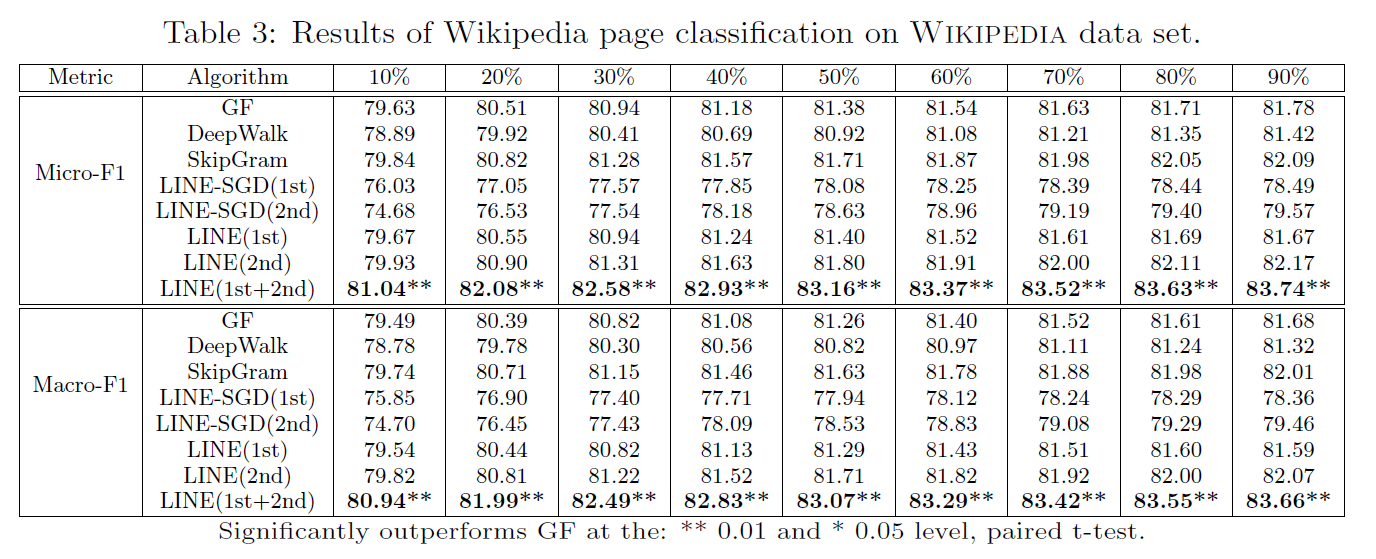
另一种评估单词嵌入的质量的方法是使用单词向量去计算文件表征,来评估文件分类任务。为了获取文件表征,由于目标是比较不同单词嵌入方法在文件分类中的应用表现以找到最好的方法,所以通过计算文本中所有单词向量表征的均值来简单获取文件的表征。实验下载了维基百科的摘要和分类。选择7个类别,包括艺术,历史,人文,数学,自然,科技,运动。对于每个类别,随机选择了10000文章,并且剔除了那些属于多个目录下的文章。我们随机按照不同的百分比来取样用于训练,并将剩下的用于评估。均选择LibLinear 包的一对多的线性回归分类器,使用micro-F1和macro-F1作为分类指标,通过对不同的训练数据进行采样,将结果平均在10次不同的运行中。
表三展示了维基百科页面分类结果。与单词分析任务可以得到相同的结论。由于Deepwalk忽视边的权重,图分解方法比DeepWalk的表现更好。LINE-SGD由于边的权重偏差过大表现较差。经过边取样处理优化后的LINE比直接应用SGD的表现略好。LINE(2nd)表现优于LINE(1st),且轻微优于图分解。在有监督的学习任务中,LINE(1st)和LINE(2nd)学习的向量直接合并是可行的。
表4展示了给定单词使用一阶相似度和二阶相似度得到的最相似的单词。根据上下文相似度,使用二阶相似度召回的最相似单词都是语义相关的单词。而一阶相似度召回的最相似单词是语义和句法混合相关的单词。

5.2.2 社交网络
社交网络比语言网络更加稀疏,尤其是Youtube。我们通过多分类任务来评估顶点。
(一)Flickr network
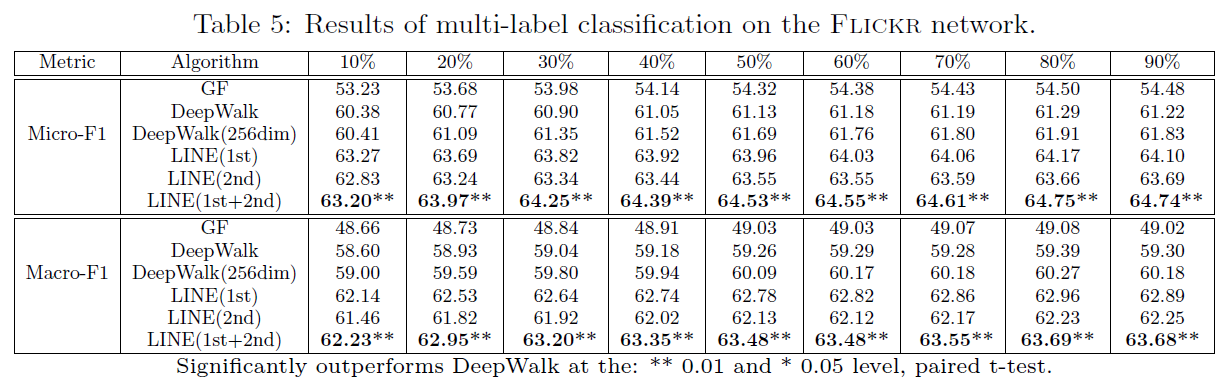
LINE(1st+2nd)表现显著优于其他方法。与语言网络相反的是,LINE(1st)表现略微优于LINE(2nd),原因可能有两个(1)在社会网络中1阶相似度比2阶相似度要更加重要,因为他表示更强的链接;(2)当网络过于稀疏,且节点的邻节点数量平均值较低时,二阶相似度可能会不太准确。LINE(1st)表现优于图分解方法,表示它在建模一阶相似度上具有更好的能力。LINE(2nd)表现优于DeepWalk方法,证明了它在建模二阶相似度上具有更强的能力。
(二)Youtube 网络
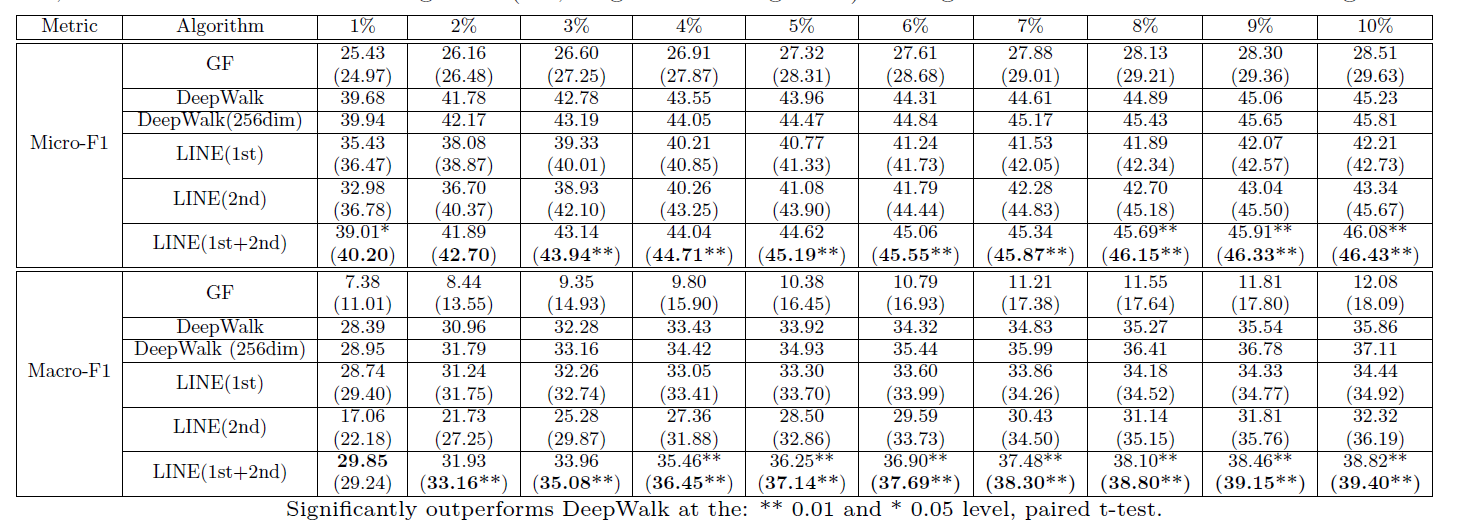
表6展示了Youtube网络(很稀疏,且平均度数低至5)上的结果。在使用不同百分比的训练数据得到的所有情况下,LINE(1st)表现优于LINE(2nd),与FLICKR网络中一样。由于其巨大稀疏性,LINE(2nd)的表现低于DeepWalk。但LINE(1st+2nd)的性能不论是在128还是256维度上都表现得很好,证明了两种相似度是互补的。
Deepwalk 使用截断的随机游走(DFS)来应对网络的稀疏性。这样通过引入非直接邻节点来消除稀疏性,可能会导致引入远距离的节点。更可靠的方法是使用广度优先策略来拓展每个节点的邻居。即递归的增加邻居的邻居。为了验证,我们拓展了所有度数低于1000的节点的邻居节点直到它的邻节点的数量达到1000,但这并没有进一步提高性能。
这样重建的网络的结果在表6中括号中展示。GF, LINE(1st)和LINE(2nd)都得到了提升,尤其是LINE(2nd)。在这个重建网络中,LINE(2nd)在所有情况下的表现都优于DeepWalk.LINE(1st+2nd)在重建后的网络上的表现没有太大的提升。这表示原始网络中的一阶相似度和二阶相似度已经捕获了大部分的原始网络中的信息。
5.2.3 引用网络
我们在两个引用网络中表示了结果,两个都是有向的。使用一阶相似度的GF和LINE不能应用于有向网络,所以文章只比较了Deepwalk和LINE(2nd)。我们选择7个流行的会议AAAI, CIKM, ICML, KDD, NIPS,SIGIR, and WWW作为分类lebel。假定在会议中发布的论文或会议中发表的作者属于与会议相对应的类别。
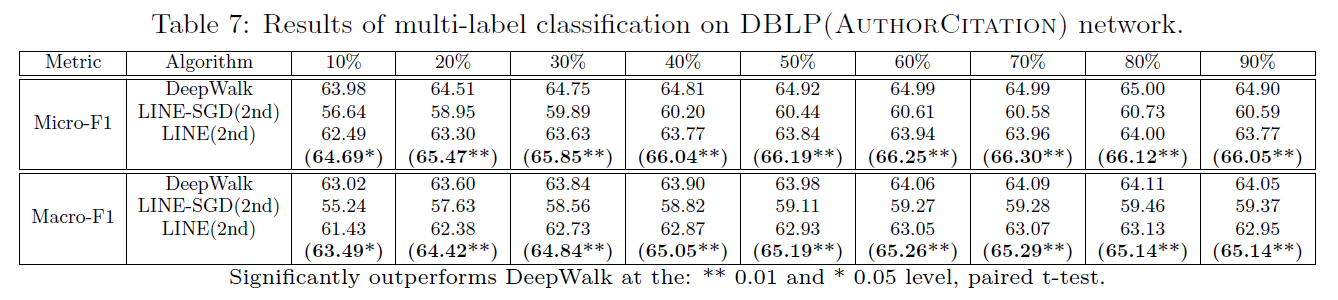
(一) DBLP(作者引用)网络
表7展示了结果。由于网络非常稀疏,DeepWalk表现优于LINE(2nd).然而通过对度数小于500的顶点递归增加邻节点的邻节点来重建网络,LINE(2nd)的表现得到显著的提升并赶超Deepwalk。直接通过随机梯度下降优化的LINE模型表现并没有像期望一样好。
(二)DBLP(论文引用)网络
表8展示了结果,LINE(2nd)表现显著优于DeepWalk。这是因为论文引用网络使用随机游走只能沿着引用路径寻找论文(即,更早的论文)。而不能到达其他的参考文献。而LINE(2nd)根据论文的引用来表示每个论文的方式更加合理。结合对低度数的节点(度数<200)进行填充处理的重构网络的LINE(2nd)方法具有进一步的性能提升。

5.3 网络布局
我们将网络嵌入到二维空间进行可视化。从DBLP数据中分离了共著网络进行了可视化。我们从三个不同的搜索领域中选取了几个会议,数据挖掘(WWW,KDD),机器学习(NIPS,ICML),计算机视觉(CVPR,ICCV)。过滤掉度数小于3的节点,最后网络包含18561个作者和207074条边。由于这三个领域非常相近,所以可视化共著者网络的难度较大。首先,我们使用多种嵌入方法把共著者网络映射到低维向量空间,然后进一步把低维向量使用t-SNE方法映射到2D空间中。图2比较了不同嵌入方法的可视化结果,图分解方法的可视化结果没有太大的意义,相同社团的作者并没有聚集在一起。Deepwalk的效果更好一些。然而,许多属于不同社团的作者被紧密聚合在中心区域,其中大多数都是在原网络中具有高度数的顶点。这是因为Deepwalk使用一个基于随机游走的方法补充顶点的邻居,由于随机性带来了大量的噪声,尤其是在具有更高度数的顶点。LINE(2nd)的表现相当好且产生了有意义的网络布局。(相同颜色的节点分布的更近)

5.4 网络稀疏与性能相关性
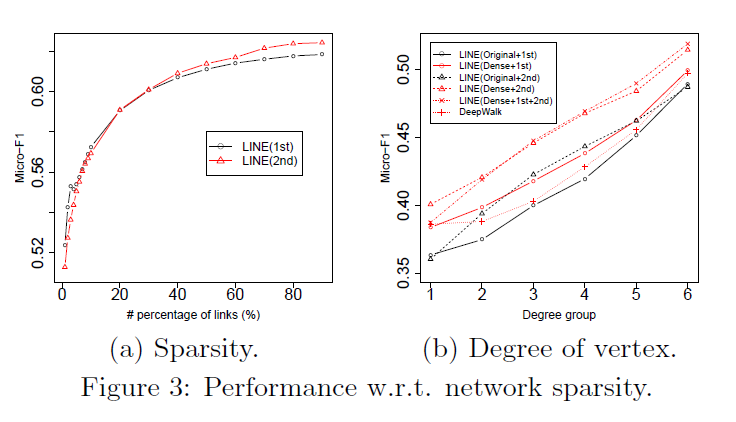
在该子节中,我们形式化的分析了以上模型性能如何受网络稀疏性影响。我们首先研究了网络稀疏性如何影响LINE(1st)和LINE(2nd)。图3a展示了FLICKR网络下关于连接百分比的结果。我们选择了比Youtube更稠密的FLICKR网络。我们可以看到,刚开始,在网络非常稀疏的情况下,LINE(1st)比LINE(2nd)表现更好,当逐渐增加链路百分比时,LINE(2nd)表现比LINE(1st)更强。这说明了二阶相似度在网络十分稀疏的情况下是表现不良的,但当节点有足够多的邻节点时,表现会优于一阶相似度。图3b展示了在原始Youtube网络和经过重建的Youtube网络上顶点度数的与性能的关系。我们把顶点根据它们度数所在的区间分类到不同目录下(0,1], [2,3], [4,6], [7, 12],[13,30],[31,+)。然后评估了不同组顶点的性能。总的来说,当节点度数增加时,不同模型的性能也会有所提升。在原始网络中,除了第一组,LINE(2nd)的表现优于LINE(1st),证明了二阶相似度在度数较低的情况下不能更好的被利用。在重建后的稠密网络。LINE(1st)和LINE(2nd)的性能都优素提升,尤其是保留了二阶相似度的LINE(2nd)。我们还可以看到LINE(2nd)在重建网络上的表现每一组都优于Deepwalk。
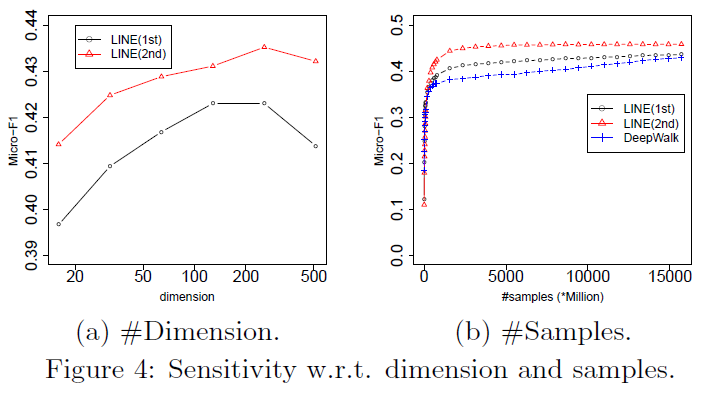
5.5 参数敏感性
接下来,文章研究了维度d参数与性能的相关性和在重建后的Youtube网络下不同模型的收敛性与样本数量的相关性。图4a记录了LINE模型与维度d的关系。我们可以发现LINE(1st)和LINE(2nd)的性能在维度过大时性能骤减。图4b展示了LINE和Deepwalk与优化过程中的样本数量的相关性。LINE(2nd)表现始终优于LINE(1st)和DeepWalk。LINE(1st)和LINE(2nd)都比Deepwalk的收敛速度要快。
5.6 可拓展性
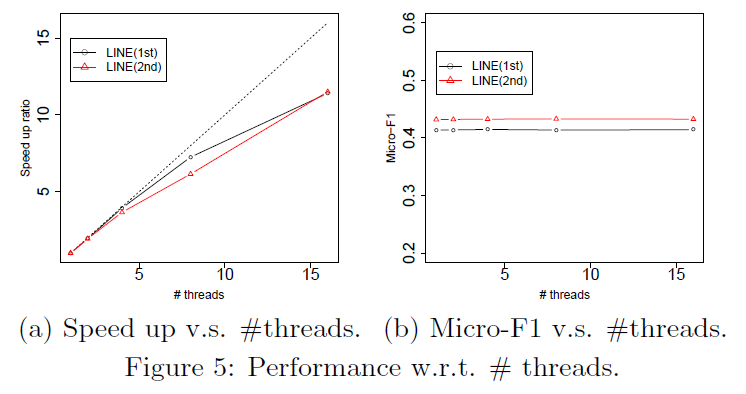
最后通过部署多个线程进行优化来研究了LINE模型经过边取样处理和异步梯度下降优化后的LINE模型的可拓展性。。图5a展示了在Youtube数据集上线程数量与速率的关系。关系相当接近于线性关系。图5b展示了在模型更新时使用多个线程下的分类性能保持平稳。这两个图共同展示了LINE模型的推理算法是可拓展的。
【Graph Embedding】line