【Spark】分类和回归算法-回归
本节主要讲Spark ML中关于回归算法的实现。示例的算法Demo包含:线性回归、广义线性回归、决策树回归、随机森林回归、梯度提升树回归等。
本节主要讲Spark ML中关于回归算法的实现。示例的算法Demo包含:线性回归、广义线性回归、决策树回归、随机森林回归、梯度提升树回归等。
本节主要讲Spark ML中关于分类算法的实现。示例的算法Demo包含:LR、DT、RF、GBTs、多层感知器、线性支持向量机、One-vs-Rest分类器以及NB等。
Spark MLlib中关于特征处理的相关算法,大致分为以下几组:
本文介绍第二组: 特征转换器(Transformers)
Spark MLlib中关于特征处理的相关算法,大致分为以下几组:
本文介绍第一组: 特征提取器(Extractors)
在本节中,我们将介绍ML Pipelines的概念。 ML Pipelines提供了一组基于DataFrame构建的统一的高级API,可帮助用户创建和调整实用的机器学习流程。
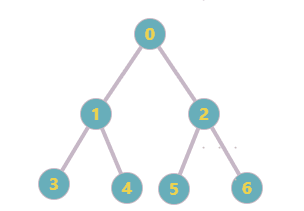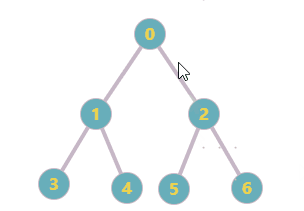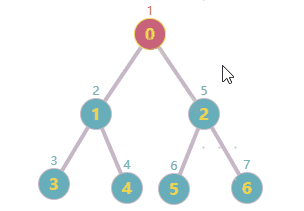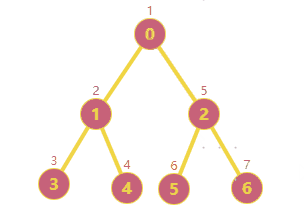
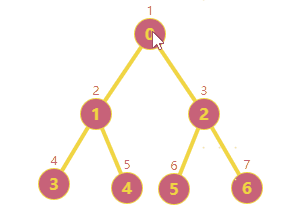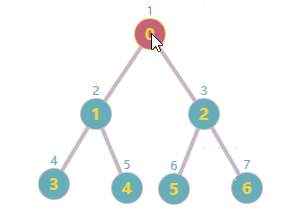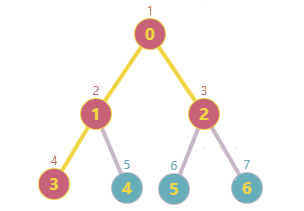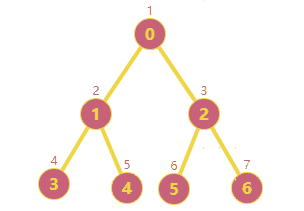
前面项目在做一个遍历搜索的时候,有用到深度/广度搜索的相关知识;原理很简单,不再拾人牙慧了;这篇文章主要是将我自己简单实现的深广度搜索分享出来并与Python networkx模块中的已有实现做一个简单对比。
主要总结了交叉熵、KL散度、JS散度和wasserstein距离(也称推土机距离,EMD)的相关知识,其中EMD的直观表示可以参见下图:

对应分布为$p(x)$的随机变量,熵$H(p)$表示其最优编码长度。交叉熵(Cross Entropy)是按照概率分布$q$的最优编码对真实分布为$p$的信息进行编码的长度,
信息论(Information Theory)是数学、物理、统计、计算机科学等多个学科的交叉领域。信息论是由Claude Shannon 最早提出的,主要研究信息的量化、存储和通信等方法。这里,“信息”是指一组消息的集合。假设在一个噪声通道上发送消息,我们需要考虑如何对每一个信息进行编码、传输以及解码,使得接收者可以尽可能准确地重构出消息。
在机器学习相关领域,信息论也有着大量的应用。比如特征抽取、统计推断、自然语言处理等。
优化问题一般都是通过迭代的方式来求解:通过猜测一个初始的估计$x_0$,然后不断迭代产生新的估计$x_1, x_2, … x_t$,希望$x_t$最终收敛到期望的最优解$x^∗$。
一个好的优化算法应该是在一定的时间或空间复杂度下能够快速准确地找到最优解。同时,好的优化算法受初始猜测点的影响较小,通过迭代能稳定地找到最优解$x^∗$的邻域,然后迅速收敛于$x^∗$。
优化算法中常用的迭代方法有线性搜索和置信域方法等。线性搜索的策略是寻找方向和步长,具体算法有梯度下降法、牛顿法、共轭梯度法等。在文章中也简要介绍过梯度下降的概念,这里为使得整个体系完整故重新记录一下。